彩りの大地 ネタスクエア
文字コード指定保存における勘違い
サブタイは”愚痴”です。
某NTTにおいてとあるシステムを動かす際にデータとなるテキストファイルを入れて運用するという開発の話。
検証環境でシステムを動かしたところ、うまく動作しなかったらしく、
システムに取り込んだテキストファイルをDLして検証したところ文字化けが発生していたため、
某NTT某所から動かない原因として指摘があったというもの。
文字化けということでテキストファイルはシステムの要件としてもUTF8である必要があることも強く言われることとなる。
ということで、担当エンジニアは問題の文字化け箇所を除去し、
テキストファイルをUTF8に保存してシステムに取り込みなおして動かしたのだがそれでもうまく稼働せず。
その際の原因として指摘されたのは、取り込んだテキストファイルをDLしたらSJISだったこと。
あれほど言ったのになんでUTF8になっていないんだと強くお叱りを受けてへこんでいた担当エンジニア。
そんな中、私の過去の経験則で(主に個人的趣味による失敗から学んだ)反論劇が幕を開けることとなる。
その結果、システムがうまくいかなかった要因については別要因であったことが判明することになった……
コンピュータの世界には本来日本語なんていうものはありません。
しかし、日本人が見て理解する上では日本語が使用出来なければ理解できません。
そこで登場するのが文字コードという考え方です。
ISO-2022-JP(日本語JISコード) 日本語のメール送受信では標準 Shift_JIS(ASCII・半角文字混在型) 日本語WindowsOS標準 EUC-JP(Extended UNIX Code Packed Format for Japanese) 日本語UNIX系OS標準 UTF-8(Unicode UTF-8) HTML5以降では推奨
詳細は検索してもらえればいいと思いますので概要だけ。
コンピュータは日本語をはじめとする文字を表現するのに数字(文字アドレス)だけで判断しています。
例えば1番が「あ」で2番が「い」、3番が「う」みたいな感じです。
実際にはコンピュータなので0と1のビットで番号を振っているので、0000番が「あ」で0001番が「い」、0010番が「う」みたいな感じです。
ところが、文字コードによっては1000番が「あ」で1001番が「い」、1010番が「う」に割り当てられており、
そういう場合は基本的に0000番、0001番、0010番には別の文字が割り当てられていることになります。
そうです、要するにこの差分が文字化けを起こす要因で、編集した際にこの文字コードの指定が正しくないことで起こりえます。
つまり、まずは文字コードを気にしないことには自分が伝えたい事が伝わらないことにもなりかねないのです。
使い勝手がよろしくないので使う可能性はないと思いますが、一応。
他のテキストエディタであれば文字コードを指定して保存する機能を持ち合わせていますが、こいつだけは例外です。
保存時の選択として、ANSIかUnicode(UTF8かUTF16)しかありません。
なんだろANSIって……それにUTF以外の他のコードないじゃん、意味が解らん……そう思った人、簡単な話です。
ANSIはOSで使える文字の中でも原始と言える存在で、文字コードにかかわらず常に同じアドレスで呼び出されます。
なお、そのANSIコードというのは基本的に半角文字のアルファベットや数値と記号などで構成されているものです。
例えばShift_JISの保存で0000番が「0」で0001番が「1」、0010番が「2」という感じなら、
それが例えUTFだろうとEUCだろうとJP版だろうとUS版だろうと0000番が「0」で0001番が「1」、0010番が「2」であることに変わりないのです。
というより、そもそもこれについては文字コードという概念すらありません。
というのも、ANSIの範囲の文字に関しては記載した通り、文字コードにかかわらず常に同じアドレスで呼び出される文字であるため、
言ってしまえば文字コードに依存しない文字ということであり、文字化けとは無縁の文字であるとも言えます。
では、ANSIの範囲の文字は文字コードというものの範囲外の文字であるのなら、
メモ帳でANSIで保存した場合、文字コードの範囲内の文字があるのにその文字はどう扱われるんだということになりますが、
実はそんなに難しい話ではありません。
Shift_JIS(ASCII・半角文字混在型) 日本語WindowsOS標準
はーい、そうでーす。正解はShift_JISでーす。
日本語Windowsを使っているので文字コードはOS依存のShift_JISにしかなりませーん。
メモ帳ゆえの最低限かつ低機能エディタであるため文字コードなんていう小難しいことは考えず、
素直にWinOS依存の文字コード、つまりShift_JISにしかならないよってわけです。
最近ではUTF保存も可能ですが、その指定がなければ無条件でShift_JIS保存で強制されるのです。
※もちろん、ほかの言語のWindowsだったらそちらに従う動作になります。
また、Unicode体系であるUTFでの保存機能を持ち合わせているのは、
恐らくWindowsのシステム部ではUnicode体系の文字を扱っているからだと思います。
そのため、TeraPadだろうがサクラエディタだろうが、
特に文字コードの設定や指定が無ければデフォルトではShift_JISでの保存が選択されるハズです。
ということはつまり、ほかの言語のWinOSを使う場合はまた違う文字コードが指定されるので注意が必要だと思えばいいです。
繰り返しになりますが、ANSIコードは文字コード体系とは関係のない文字群です。
そのため、ANSIコードのみで構成されているテキストファイルは文字コードの影響は受けません。
それがたとえUTF8で開こうがShift_JISで開こうが、EUC-JPで開こうが同じことです。
つまり、ANSIコードのみ(空ファイルも同様)で構成されているテキストファイルには文字コードという扱いが無いので、
日本語WindowsOSの場合、どのテキストエディタも無条件でOS依存のShift_JISで開こうとします。
実際にやってみるとわかります。
テキストエディタでANSIコード内の文字のみを使ってファイルを保存します(空ファイルでも同じことです)。
たとえばTeraPadを用いて「test」という文字列で保存する際にUTF-8を指定して保存します。
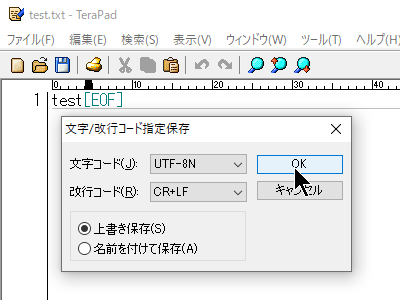
そしていったん閉じて、再度そのファイルをTeraPadで開いてみるとどうでしょうか、
SJIS(Shift_JIS)で開かれていることがわかります。
は?何言ってんの?ちゃんとUTF8で開くか聞いてくるじゃねーか、デタラメいってんじゃねーぞ!
そう思った方、さてはTeraPadではありませんね。
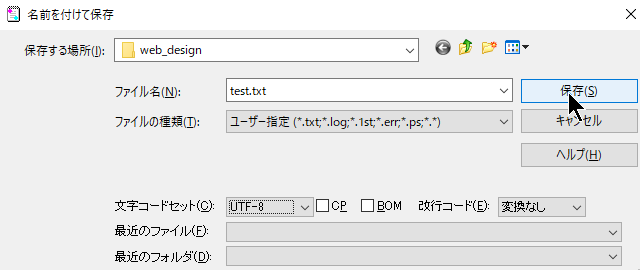
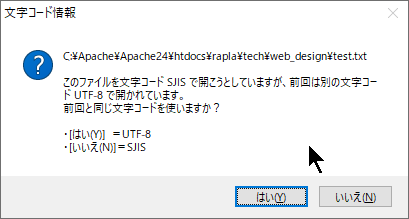
画像ではサクラエディタで同様のことをやった場合ですが、Open時に文字コードの問い合わせがあります。
前回保存した際の文字コードはUTF8だが、どういうわけかSJISで開こうとする謎の挙動が見られます。
つまり、SJISで開こうとしているのはあくまで保存状態がSJISであるためで、
UTF8を指定して保存したハズが、実際にはSJISで保存されていることがわかります。
サクラエディタでこのような問い合わせがあるのはサクラエディタ側で情報を保持しているためにおこることであり、
実際に保存場所を移動やコピーなどして変えてから開いてみる(キャッシュが働いているせいか移動だけではダメな模様)
とこのような問い合わせはなく、無条件でSJISで開く動作となります。
要はあくまで無条件でJPのWindowsOS依存のShift_JISで開かれることになるということです。
何故そんな動作になるのかというと冒頭のおさらいにも書かれている通り、
ANSIコードについてはどのOS(基本はUNIX系)でも扱える文字の中では原始的な存在であることから、
異OS間でも一定の文字アドレス帯には必ず同じ文字アドレスを格納しています。
つまり、ANSIコード体系のみの文字だけが保存されているファイルの場合、
異OS間でも一定の文字アドレス帯には必ず同じ文字アドレスを格納している文字だけが書かれているファイルである以上はわざわざ文字コード情報まで保存する必要がないため、
そんな要らない情報までわざわざ保存するようなことまではしていません。
そして、JPのWindowsOSは文字コード情報がないファイルについてはOS独自の判断で自分のファイルシステム標準の文字コードで開こうとしているため、
勝手にShift_JISだと解釈してShift_JISで開くようになっていると、ただそれだけの話なのです。
そしてサクラエディタは、そのうえで前回そのファイルを保存した際の文字コード情報をサクラエディタ側で独自に保存しているため、
ユーザに対する問い合わせが発生し、どうするかユーザに委ねる動作になっています。
(逆に保存内容が「テスト」という文字コード依存の内容を格納している場合は無条件でUTF8で開かれるハズです。)
要は、ANSIコード体系のみの文字だけが保存されているファイルの場合、
UTF-8はおろか、そもそも文字コードを指定して保存するという選択肢すら与えられていないのです。
一応保存時に指定できるのは見かけ上の話でしかなく、
実際にはこの手のファイルに対する文字コードの指定保存は機能しません。
ただし、裏を返せばANSIコード体系のみの文字だけが保存されているテキストファイルであれば
(少なくとも動かすシステムがUNIX系のそれであれば)不具合なく動くことだけは間違いないので、
そもそも文字コードの違いでシステムが動きませんという理由にはならず、
明らかに別要因である可能性のほうが高くなっています。
※実際、冒頭の経緯の話にもある文字化けを起こしていた箇所はそもそもコメントアウトされている部分であるため、
実際にはシステムの動作に影響を与えようがない。
なお、コメントアウトの際には行頭に「;」を入力する必要があるが、
「;」もANSIコード体系の文字であるため文字化けしない。
だからもし、「UTF8で保存しろって言ったのになんで変わってないんだ!」「UTF8で保存しろといっただろ!」などと、
どこそかのボンクラSE……ロートルSE……老害……三流SE……無能SE……とにかくどっかのマヌケなSEがそんなことをほざき始めたら、
自分たちのプロジェクトが恥をかく前にちゃんと説明してあげてください。
特に特に一番やらかしてはいけないレベルの上位SEがそんなことをやらかしているなんてなったら目も当てられません。
まったく……そんなわけで案外SEのハードルなんてもんは低いもんです。正直、誰でも簡単にSEになれると思います、困ったもんだ。